Visible Consonants
About
Visible Consonants is a web app for the analysis of acoustic consonant measurements. The app is an useful instrument for research in phonetics, sociolinguistics, dialectology, forensic linguistics, and speech-language pathology. The following people were involved in the development of Visible Consonants: Wilbert Heeringa (implementation), Hans Van de Velde (project manager), Vincent van Heuven (advice). Visible Consonants is still under development. Comments are welcome and can be sent to
 .
.
System requirements
Visible Consonants runs best on a computer with a monitor with a minimum resolution of 1370 x 870 (width x height). The use of Mozilla Firefox as a web browser is to be preferred.
Format
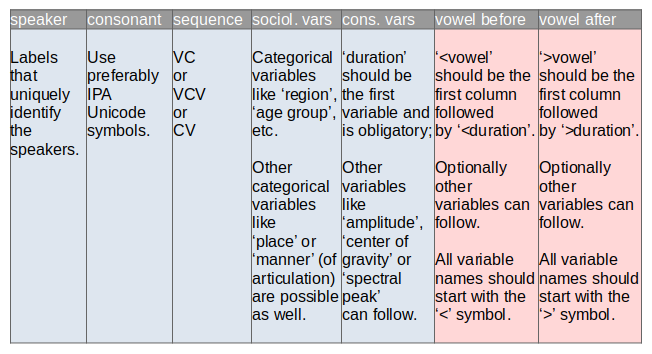
The input file should be a spreadsheet that is created in Excel or LibreOffice. It should be saved as an Excel 2007/2010/2013 XML file, i.e. with extension '.xlsx'. The spreadsheet should include the following variables (shown in red):
-
General
-
speaker
Contains the speaker labels. This column is obligatory.
-
consonant
Contains the consonant labels. Multiple pronunciations of the same consonant per speaker are possible. In case you want to use IPA characters, enter them as Unicode characters. In order to find Unicode IPA characters, use the online
IPA Chart Keyboard
of Weston Ruter. This column is obligatory.
-
sequence
Indicates the context in which a consonant appears. Should be VC, VCV or CV. This column is obligatory.
-
Sociolinguistic
-
...
An arbitrary number of columns representing categorical variables such as location, language, gender, age group, etc. may follow, but is not obligatory. See to it that each categorical variable has an unique set of different values. Prevent the use of numbers, rather use meaningful codes. For example, rather then using codes '1' and '2' for a variable 'age group' use 'old' and 'young' or 'o' and 'y'.
-
Consonant
-
duration
Durations of the consonants. The measurements may be either in seconds or milliseconds. This column is obligatory.
-
...
Any number of numerical variables such as amplitude, intensity, etc.
-
time var1 var2 ...
A set of variables that occurs multiple times. The variable 'time' gives the time point within the consonant interval in seconds or milliseconds, i.e. it is assumed that the consonant interval starts at 0 (milli)seconds. The variables should be measured at the time given in the column 'time'. The program assumes that spectral variables, if any, are measured in Hertz and not normalized. A set may be repeated as
many times
as the user wishes, but should occur at least two times. For each repetition the same column names should be used.
In order to visualize formant transitions of vowels preceding a consonant, the following variables should be added:
-
Vowel before consonant
-
<vowel
The label of the vowel that precedes the consonant. In case you want to use IPA characters, enter them as Unicode characters. This column is obligatory.
-
<duration
The measurements may be either in seconds or milliseconds. This column is obligatory but may be kept empty.
-
...
Any number of numerical variables. They should be given for the consonant as well.
-
<time <f0 <F1 <F2 <F3
A set of five columns should follow multiple times: '<time', '<f0', '<F1', '<F2' and '<F3'. The variable '<time' gives the time point within the vowel interval in seconds or milliseconds, i.e. it is assumed that the vowel interval starts at 0 (milli)seconds. The f0, F1, F2 and F3 should be measured at the time given in the column '<time'. The program assumes that they are measured in Hertz and not normalized. The set of five columns may be repeated as list(name = "em", attribs = list(), children = list("many times")) as the user wishes, but should occur at least two times. For each repetition the same column names should be used. A set should always include all five columns, but the columns '<f0' and '<F3' may be kept empty.
In order to visualize formant transitions of vowels following a consonant, the following variables should be added:
-
Vowel after consonant
-
>vowel
The label of the vowel that precedes the consonant. In case you want to use IPA characters, enter them as Unicode characters. This column is obligatory.
-
>duration
The measurements may be either in seconds or milliseconds. This column is obligatory but may be kept empty.
-
...
Any number of numerical variables. They should be given for the consonant as well.
-
>time >f0 >F1 >F2 >F3
A set of five columns should follow multiple times: '>time', '>f0', '>F1', '>F2' and '>F3'. The variable '>time' gives the time point within the vowel interval in seconds or milliseconds, i.e. it is assumed that the vowel interval starts at 0 (milli)seconds. The f0, F1, F2 and F3 should be measured at the time given in the column '>time'. The program assumes that they are measured in Hertz and not normalized. The set of five columns may be repeated as list(name = "em", attribs = list(), children = list("many times")) as the user wishes, but should occur at least two times. For each repetition the same column names should be used. A set should always include all five columns, but the columns '>f0' and '>F3' may be kept empty.
The structure of the input file can be visualized schematically as follows:
Graphs
Graphs can be saved in six formats: JPG, PNG, SVG, EPS, PDF and TEX. TEX files are created with TikZ. When using this format, it is assumed that XeLaTeX is installed. Generating a TikZ may take a long time. When including a TikZ file in a LaTeX document, you need to use a font that supports the IPA Unicode characters, for example: 'Doulos SIL', 'Charis SIL' or 'Linux Libertine O'. You also need to adjust the left margin and the scaling of the graph. The LaTeX document should be compiled with
xelatex
. Example of a LaTeX file in which a TikZ file is included:
\documentclass{minimal}
\usepackage{tikz}
\usepackage{fontspec}
\setmainfont{Linux Libertine O}
\begin{document}
{\hspace*{-3cm}\scalebox{0.8}{\input{formantPlot.TEX}}}
\end{document}
Implementation
This program is implemented as a Shiny app. Shiny was developed by RStudio. This app uses the following R packages:
-
base
R Core Team (2017). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/
-
shiny
Winston Chang, Joe Cheng, J.J. Allaire, Yihui Xie and Jonathan McPherson (2017). shiny: Web Application Framework for R. R package version 1.0.0. https://CRAN.R-project.org/package=shiny
-
shinyBS
Eric Bailey (2015). shinyBS: Twitter Bootstrap Components for Shiny. R package version 0.61. https://CRAN.R-project.org/package=shinyBS
-
shinyjs
Dean Attali (2018). shinyjs: Easily Improve the User Experience of Your Shiny Apps in Seconds. R package version 1.0. https://CRAN.R-project.org/package=shinyjs
-
tidyr
Hadley Wickham and Lionel Henry (2019). tidyr: Tidy Messy Data. R package version 1.0.0. https://CRAN.R-project.org/package=tidyr
-
PBSmapping
Jon T. Schnute, Nicholas Boers and Rowan Haigh (2019). PBSmapping: Mapping Fisheries Data and Spatial Analysis Tools. R package version 2.72.1. https://CRAN.R-project.org/package=PBSmapping
-
formattable
Kun Ren and Kenton Russell (2016). formattable: Create 'Formattable' Data Structures. R package version 0.2.0.1. https://CRAN.R-project.org/package=formattable
-
ggplot2
H. Wickham (2009). ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York. http://ggplot2.org
-
ggrepel
Kamil Slowikowski (2017). ggrepel: Repulsive Text and Label Geoms for 'ggplot2'. R package version 0.7.0. https://CRAN.R-project.org/package=ggrepel
-
readxl
Hadley Wickham and Jennifer Bryan (2017). readxl: Read Excel Files. R package version 1.0.0. https://CRAN.R-project.org/package=readxl
-
WriteXLS
Marc Schwartz and various authors. (2015). WriteXLS: Cross-Platform Perl Based R Function to Create Excel 2003 (XLS) and Excel 2007 (XLSX) Files. R package version 4.0.0. https://CRAN.R-project.org/package=WriteXLS
-
DT
Yihui Xie (2016). DT: A Wrapper of the JavaScript Library 'DataTables'. R package version 0.2. https://CRAN.R-project.org/package=DT
-
pracma
Hans Werner Borchers (2017). pracma: Practical Numerical Math Functions. R package version 1.9.9. https://CRAN.R-project.org/package=pracma
-
plyr
Hadley Wickham (2011). The Split-Apply-Combine Strategy for Data Analysis. Journal of Statistical Software, 40(1), 1-29. http://www.jstatsoft.org/v40/i01/
-
svglite
Hadley Wickham, Lionel Henry, T Jake Luciani, Matthieu Decorde and Vaudor Lise (2016). svglite: An 'SVG' Graphics Device. R package version 1.2.0. https://CRAN.R-project.org/package=svglite
-
Cairo
Simon Urbanek and Jeffrey Horner (2015). Cairo: R graphics device using cairo graphics library for creating high-quality bitmap (PNG, JPEG, TIFF), vector (PDF, SVG, PostScript) and display (X11 and Win32) output. R package version 1.5-9. https://CRAN.R-project.org/package=Cairo
-
tikzDevice
Charlie Sharpsteen and Cameron Bracken (2020). tikzDevice: R Graphics Output in LaTeX Format. R package version 0.12.3.1. https://CRAN.R-project.org/package=tikzDevice
-
shinybusy
Fanny Meyer and Victor Perrier (2020). shinybusy: Busy Indicator for 'Shiny' Applications. R package version 0.2.2. https://CRAN.R-project.org/package=shinybusy
How to cite this app
Heeringa, Wilbert & Van de Velde, Hans (2024). Visible Consonants [computer program]. Retrieved 30 January 2024 from https://www.visibleconsonants.org/.
Privacy
This app uses cookies that are used to collect data. By using this site you agree to these cookies being set. Google Analytics is used in order to track and report website traffic. See:
How Google uses data when you use our partners' sites or apps
.
Liability
This app is provided 'as is' without warranty of any kind, either express or implied, including, but not limited to, the implied warranties of fitness for a purpose, or the warranty of non-infringement. Without limiting the foregoing, the Fryske Akademy makes no warranty that: 1) the app will meet your requirements, 2) the app will be uninterrupted, timely, secure or error-free, 3) the results that may be obtained from the use of the app will be effective, accurate or reliable, 4) the quality of the app will meet your expectations, 5) any errors in the app will be corrected.
The app and its documentation could include technical or other mistakes, inaccuracies or typographical errors. The Fryske Akademy may make changes to the app or documentation made available on its web site. The app and its documentation may be out of date, and the Fryske Akademy makes no commitment to update such materials.
The Fryske Akademy assumes no responsibility for errors or ommissions in the app or documentation available from its web site.
In no event shall the Fryske Akademy be liable to you or any third parties for any special, punitive, incidental, indirect or consequential damages of any kind, or any damages whatsoever, including, without limitation, those resulting from loss of use, data or profits, whether or not the Fryske Akademy has been advised of the possibility of such damages, and on any theory of liability, arising out of or in connection with the use of this software.
The use of the app is done at your own discretion and risk and with agreement that you will be solely responsible for any damage to your computer system or loss of data that results from such activities. No advice or information, whether oral or written, obtained by you from the Fryske Akademy shall create any warranty for the software.
Other
The disclaimer may be changed from time to time.
About
Visible Consonants is a web app for the analysis of acoustic consonant measurements. The app is an useful instrument for research in phonetics, sociolinguistics, dialectology, forensic linguistics, and speech-language pathology. The following people were involved in the development of Visible Consonants: Wilbert Heeringa (implementation), Hans Van de Velde (project manager), Vincent van Heuven (advice). Visible Consonants is still under development. Comments are welcome and can be sent to
![]() .
.
System requirements
Visible Consonants runs best on a computer with a monitor with a minimum resolution of 1370 x 870 (width x height). The use of Mozilla Firefox as a web browser is to be preferred.
Format
The input file should be a spreadsheet that is created in Excel or LibreOffice. It should be saved as an Excel 2007/2010/2013 XML file, i.e. with extension '.xlsx'. The spreadsheet should include the following variables (shown in red):
-
General
-
speaker
Contains the speaker labels. This column is obligatory.
-
consonant
Contains the consonant labels. Multiple pronunciations of the same consonant per speaker are possible. In case you want to use IPA characters, enter them as Unicode characters. In order to find Unicode IPA characters, use the online IPA Chart Keyboard of Weston Ruter. This column is obligatory.
-
sequence
Indicates the context in which a consonant appears. Should be VC, VCV or CV. This column is obligatory.
-
speaker
-
Sociolinguistic
-
...
An arbitrary number of columns representing categorical variables such as location, language, gender, age group, etc. may follow, but is not obligatory. See to it that each categorical variable has an unique set of different values. Prevent the use of numbers, rather use meaningful codes. For example, rather then using codes '1' and '2' for a variable 'age group' use 'old' and 'young' or 'o' and 'y'.
-
...
-
Consonant
-
duration
Durations of the consonants. The measurements may be either in seconds or milliseconds. This column is obligatory.
-
...
Any number of numerical variables such as amplitude, intensity, etc.
-
time var1 var2 ...
A set of variables that occurs multiple times. The variable 'time' gives the time point within the consonant interval in seconds or milliseconds, i.e. it is assumed that the consonant interval starts at 0 (milli)seconds. The variables should be measured at the time given in the column 'time'. The program assumes that spectral variables, if any, are measured in Hertz and not normalized. A set may be repeated as many times as the user wishes, but should occur at least two times. For each repetition the same column names should be used.
-
duration
In order to visualize formant transitions of vowels preceding a consonant, the following variables should be added:
-
Vowel before consonant
-
<vowel
The label of the vowel that precedes the consonant. In case you want to use IPA characters, enter them as Unicode characters. This column is obligatory.
-
<duration
The measurements may be either in seconds or milliseconds. This column is obligatory but may be kept empty.
-
...
Any number of numerical variables. They should be given for the consonant as well.
-
<time <f0 <F1 <F2 <F3
A set of five columns should follow multiple times: '<time', '<f0', '<F1', '<F2' and '<F3'. The variable '<time' gives the time point within the vowel interval in seconds or milliseconds, i.e. it is assumed that the vowel interval starts at 0 (milli)seconds. The f0, F1, F2 and F3 should be measured at the time given in the column '<time'. The program assumes that they are measured in Hertz and not normalized. The set of five columns may be repeated as list(name = "em", attribs = list(), children = list("many times")) as the user wishes, but should occur at least two times. For each repetition the same column names should be used. A set should always include all five columns, but the columns '<f0' and '<F3' may be kept empty.
-
<vowel
In order to visualize formant transitions of vowels following a consonant, the following variables should be added:
-
Vowel after consonant
-
>vowel
The label of the vowel that precedes the consonant. In case you want to use IPA characters, enter them as Unicode characters. This column is obligatory.
-
>duration
The measurements may be either in seconds or milliseconds. This column is obligatory but may be kept empty.
-
...
Any number of numerical variables. They should be given for the consonant as well.
-
>time >f0 >F1 >F2 >F3
A set of five columns should follow multiple times: '>time', '>f0', '>F1', '>F2' and '>F3'. The variable '>time' gives the time point within the vowel interval in seconds or milliseconds, i.e. it is assumed that the vowel interval starts at 0 (milli)seconds. The f0, F1, F2 and F3 should be measured at the time given in the column '>time'. The program assumes that they are measured in Hertz and not normalized. The set of five columns may be repeated as list(name = "em", attribs = list(), children = list("many times")) as the user wishes, but should occur at least two times. For each repetition the same column names should be used. A set should always include all five columns, but the columns '>f0' and '>F3' may be kept empty.
-
>vowel
The structure of the input file can be visualized schematically as follows:
Graphs
Graphs can be saved in six formats: JPG, PNG, SVG, EPS, PDF and TEX. TEX files are created with TikZ. When using this format, it is assumed that XeLaTeX is installed. Generating a TikZ may take a long time. When including a TikZ file in a LaTeX document, you need to use a font that supports the IPA Unicode characters, for example: 'Doulos SIL', 'Charis SIL' or 'Linux Libertine O'. You also need to adjust the left margin and the scaling of the graph. The LaTeX document should be compiled with
xelatex
. Example of a LaTeX file in which a TikZ file is included:
\documentclass{minimal}
\usepackage{tikz}
\usepackage{fontspec}
\setmainfont{Linux Libertine O}
\begin{document}
{\hspace*{-3cm}\scalebox{0.8}{\input{formantPlot.TEX}}}
\end{document}
Implementation
This program is implemented as a Shiny app. Shiny was developed by RStudio. This app uses the following R packages:
-
base
R Core Team (2017). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. https://www.R-project.org/
-
shiny
Winston Chang, Joe Cheng, J.J. Allaire, Yihui Xie and Jonathan McPherson (2017). shiny: Web Application Framework for R. R package version 1.0.0. https://CRAN.R-project.org/package=shiny
-
shinyBS
Eric Bailey (2015). shinyBS: Twitter Bootstrap Components for Shiny. R package version 0.61. https://CRAN.R-project.org/package=shinyBS
-
shinyjs
Dean Attali (2018). shinyjs: Easily Improve the User Experience of Your Shiny Apps in Seconds. R package version 1.0. https://CRAN.R-project.org/package=shinyjs
-
tidyr
Hadley Wickham and Lionel Henry (2019). tidyr: Tidy Messy Data. R package version 1.0.0. https://CRAN.R-project.org/package=tidyr
-
PBSmapping
Jon T. Schnute, Nicholas Boers and Rowan Haigh (2019). PBSmapping: Mapping Fisheries Data and Spatial Analysis Tools. R package version 2.72.1. https://CRAN.R-project.org/package=PBSmapping
-
formattable
Kun Ren and Kenton Russell (2016). formattable: Create 'Formattable' Data Structures. R package version 0.2.0.1. https://CRAN.R-project.org/package=formattable
-
ggplot2
H. Wickham (2009). ggplot2: Elegant Graphics for Data Analysis. Springer-Verlag New York. http://ggplot2.org
-
ggrepel
Kamil Slowikowski (2017). ggrepel: Repulsive Text and Label Geoms for 'ggplot2'. R package version 0.7.0. https://CRAN.R-project.org/package=ggrepel
-
readxl
Hadley Wickham and Jennifer Bryan (2017). readxl: Read Excel Files. R package version 1.0.0. https://CRAN.R-project.org/package=readxl
-
WriteXLS
Marc Schwartz and various authors. (2015). WriteXLS: Cross-Platform Perl Based R Function to Create Excel 2003 (XLS) and Excel 2007 (XLSX) Files. R package version 4.0.0. https://CRAN.R-project.org/package=WriteXLS
-
DT
Yihui Xie (2016). DT: A Wrapper of the JavaScript Library 'DataTables'. R package version 0.2. https://CRAN.R-project.org/package=DT
-
pracma
Hans Werner Borchers (2017). pracma: Practical Numerical Math Functions. R package version 1.9.9. https://CRAN.R-project.org/package=pracma
-
plyr
Hadley Wickham (2011). The Split-Apply-Combine Strategy for Data Analysis. Journal of Statistical Software, 40(1), 1-29. http://www.jstatsoft.org/v40/i01/
-
svglite
Hadley Wickham, Lionel Henry, T Jake Luciani, Matthieu Decorde and Vaudor Lise (2016). svglite: An 'SVG' Graphics Device. R package version 1.2.0. https://CRAN.R-project.org/package=svglite
-
Cairo
Simon Urbanek and Jeffrey Horner (2015). Cairo: R graphics device using cairo graphics library for creating high-quality bitmap (PNG, JPEG, TIFF), vector (PDF, SVG, PostScript) and display (X11 and Win32) output. R package version 1.5-9. https://CRAN.R-project.org/package=Cairo
-
tikzDevice
Charlie Sharpsteen and Cameron Bracken (2020). tikzDevice: R Graphics Output in LaTeX Format. R package version 0.12.3.1. https://CRAN.R-project.org/package=tikzDevice
-
shinybusy
Fanny Meyer and Victor Perrier (2020). shinybusy: Busy Indicator for 'Shiny' Applications. R package version 0.2.2. https://CRAN.R-project.org/package=shinybusy
How to cite this app
Heeringa, Wilbert & Van de Velde, Hans (2024). Visible Consonants [computer program]. Retrieved 30 January 2024 from https://www.visibleconsonants.org/.
Privacy
This app uses cookies that are used to collect data. By using this site you agree to these cookies being set. Google Analytics is used in order to track and report website traffic. See: How Google uses data when you use our partners' sites or apps .
Liability
This app is provided 'as is' without warranty of any kind, either express or implied, including, but not limited to, the implied warranties of fitness for a purpose, or the warranty of non-infringement. Without limiting the foregoing, the Fryske Akademy makes no warranty that: 1) the app will meet your requirements, 2) the app will be uninterrupted, timely, secure or error-free, 3) the results that may be obtained from the use of the app will be effective, accurate or reliable, 4) the quality of the app will meet your expectations, 5) any errors in the app will be corrected.
The app and its documentation could include technical or other mistakes, inaccuracies or typographical errors. The Fryske Akademy may make changes to the app or documentation made available on its web site. The app and its documentation may be out of date, and the Fryske Akademy makes no commitment to update such materials.
The Fryske Akademy assumes no responsibility for errors or ommissions in the app or documentation available from its web site.
In no event shall the Fryske Akademy be liable to you or any third parties for any special, punitive, incidental, indirect or consequential damages of any kind, or any damages whatsoever, including, without limitation, those resulting from loss of use, data or profits, whether or not the Fryske Akademy has been advised of the possibility of such damages, and on any theory of liability, arising out of or in connection with the use of this software.
The use of the app is done at your own discretion and risk and with agreement that you will be solely responsible for any damage to your computer system or loss of data that results from such activities. No advice or information, whether oral or written, obtained by you from the Fryske Akademy shall create any warranty for the software.
Other
The disclaimer may be changed from time to time.